
🎬 Episode 3 : 💥 Why Chunking Makes or Breaks RAG
Ai engineer
Chunking is the hidden lever behind effective RAG. Split text too small, you lose context; too large, you add noise. In this episode, we compare fixed-size, recursive, and semantic chunking—highlighting their trade-offs and when to use each. We also cover special handling for tables so your retrieval stays accurate and reliable.
🎬 Episode 3 — 💥 Why Chunking Makes or Breaks RAGRAG
Welcome back to our RAG series! In Episode 1:[link]. we explored why Retrieval-Augmented Generation (RAG) matters for enterprises. In Episode 2:[link], we broke down the key building blocks of a RAG pipeline.
Now, in Episode 3, we delve into one of the most overlooked—but absolutely critical—design choices in RAG: chunking.
Why does the same RAG pipeline sometimes return irrelevant or incomplete answers? A common culprit is how the source content was chunked before embedding. Chunking—the way you split documents into retrievable pieces—directly affects what gets surfaced by the vector search and how coherent the final answer is. If chunks are too small, you lose context; too large, and you dilute relevance. Framework docs and vendor guides treat chunking as a first-class design decision because it gates both recall (can we find the right bit?) and precision (did we avoid dragging in noise?).
In this post we’ll treat chunking as the hidden lever behind good retrieval. We’ll compare fixed-size, recursive (hierarchical), and semantic chunking (e.g., clustering/embedding-driven) and call out concrete trade-offs so you know when to use which—and why. We’ll also touch on special handling for tables and structured content in a later section of this episode.
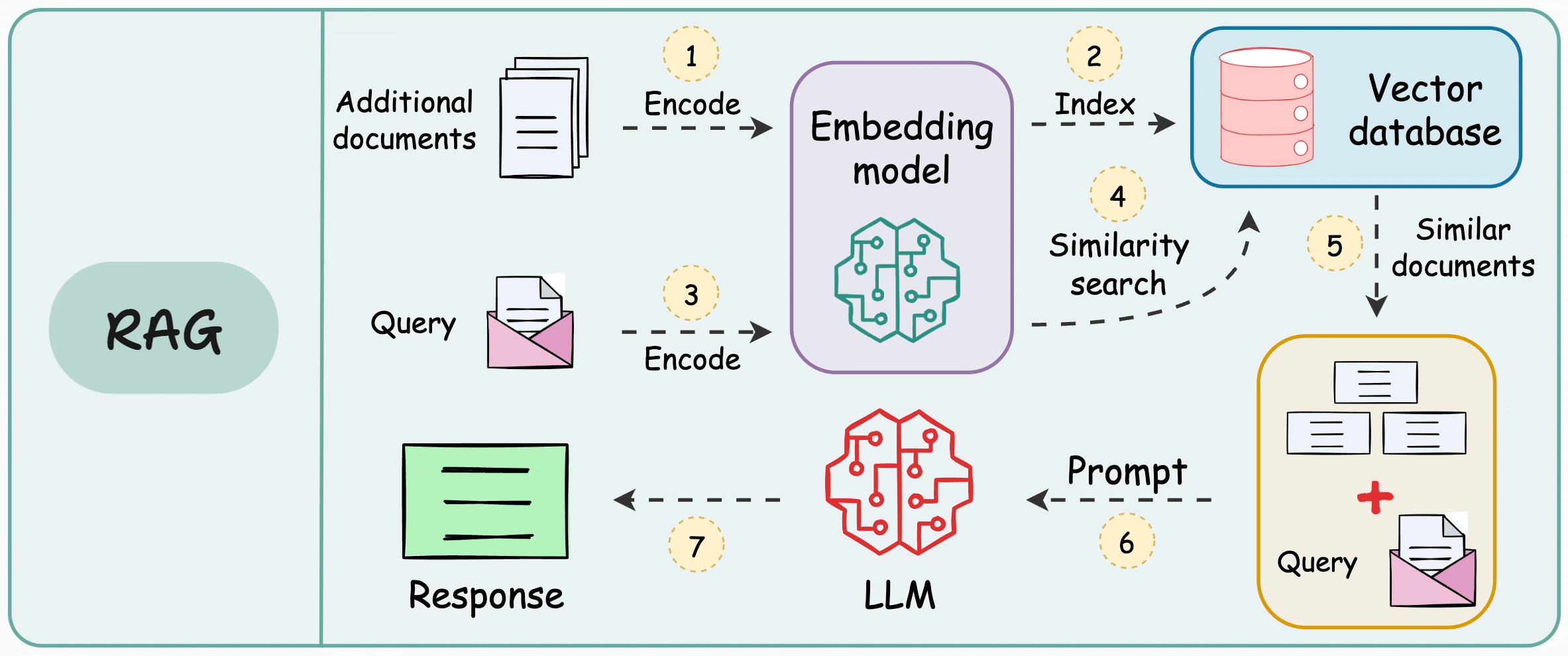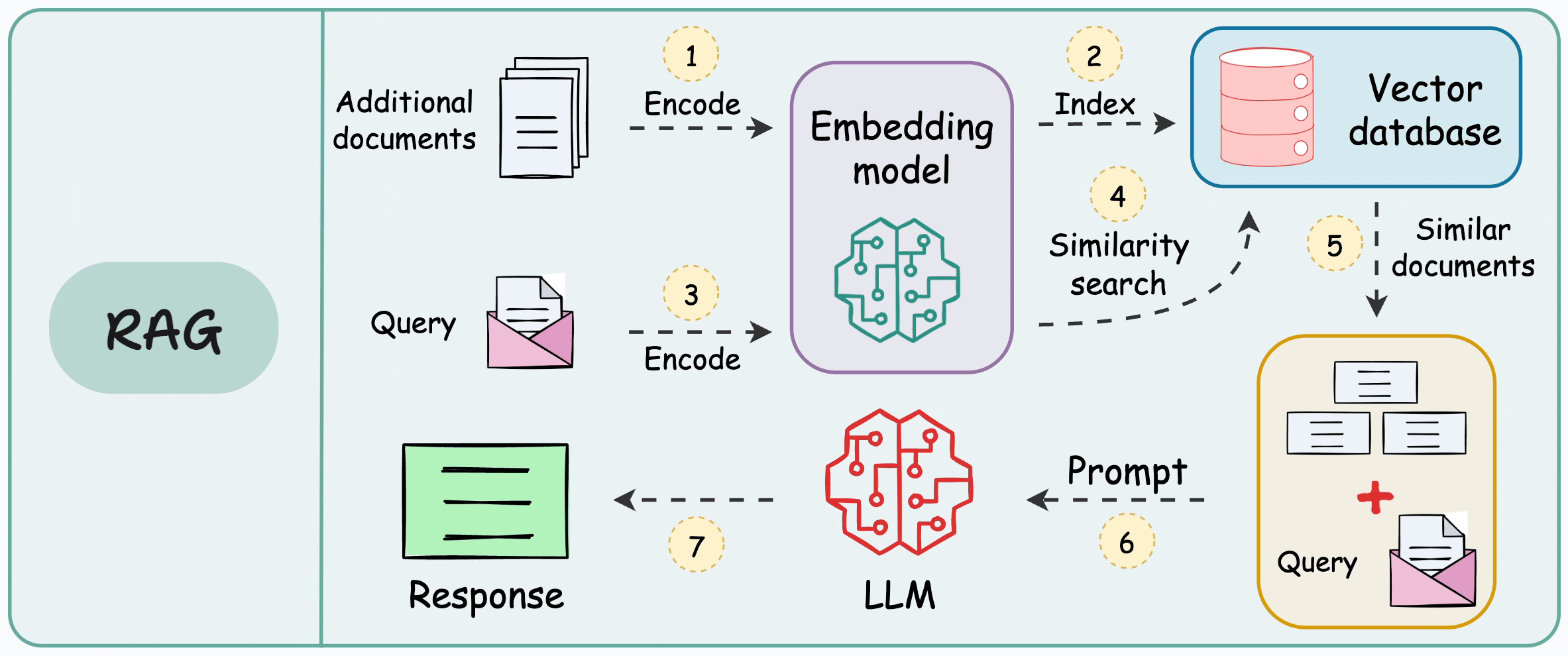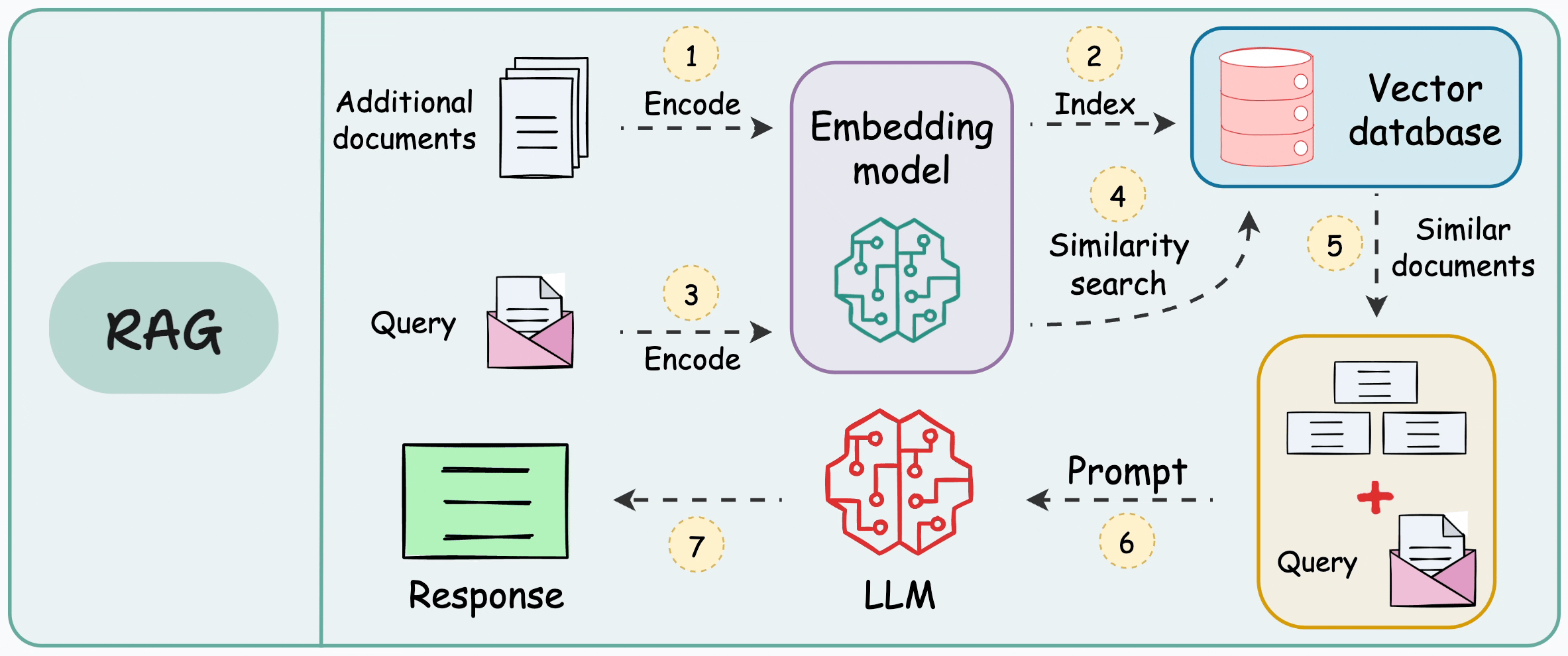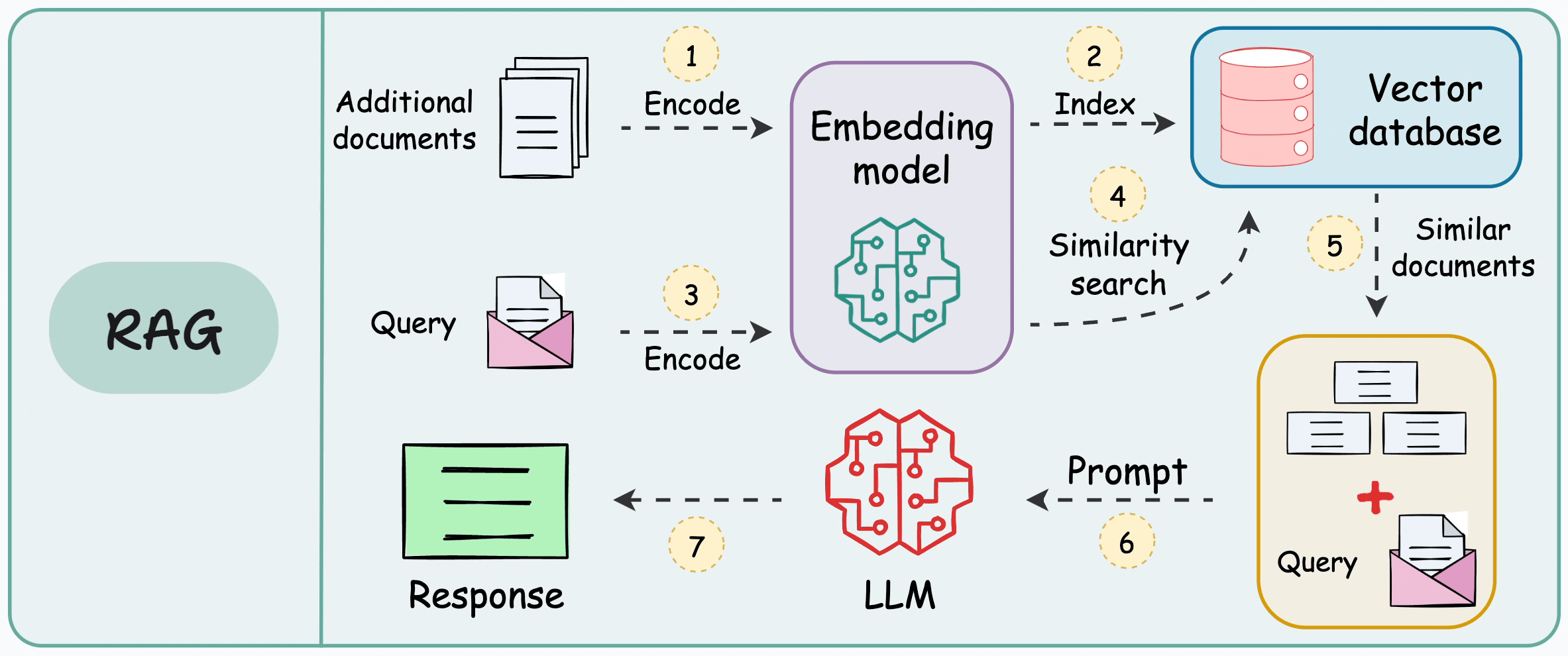
2. 🗡 What Is Chunking in RAG?
Definition. Chunking is the preprocessing step of splitting longer documents into smaller units (“chunks”) that you embed and store in a vector database for retrieval. Each chunk becomes the atomic unit of meaning the system can search and return; your retrieval quality is therefore bounded by how well those units align with real concepts.

Why not embed whole documents?
- ✨ Context/token limits. Embedding and chat models accept inputs only up to a maximum token window; long documents exceed those limits, so you must break them up. Even with today’s larger contexts, official guidance still recommends splitting long text before embedding or prompting.
- ✨ Precision & ranking. If you embed an entire document, the representation mixes multiple topics, making similarity search less discriminative. Smaller, well-formed chunks improve retrieval specificity in practice and are recommended across framework docs.
3. 🧾 Fixed-Size Chunking
How it works Fixed-size chunking is the simplest approach: split a document into equally sized pieces (for example, ~500 tokens per chunk), optionally with a small overlap (e.g., 25–100 tokens) so neighboring chunks keep some shared context. Each chunk is then embedded and indexed independently. This is the default pattern many teams try first because it is straightforward to implement.
Advantages
- Simple & deterministic. Easy to implement and reason about. Good as a baseline.
- Fast & predictable. Ingestion pipelines are uniform (same embedding cost per chunk). This helps capacity planning.
Pitfalls
- Too small → fragmented context. When a logical idea or answer spans multiple tiny chunks, retrieval may return only a fragment and the LLM won’t have enough context to generate a complete, coherent answer. (Common when you split on fixed token counts without respecting paragraph or section boundaries.)
- Too large → diluted relevance / noise. Large chunks mix multiple topics; similarity search becomes less discriminative and retrieved chunks may include irrelevant material that confuses the LLM.
Practical tip & example A common community rule-of-thumb is ~128–512 tokens, with many teams using ~300–500 tokens and a modest overlap; but the “right” size depends on your queries (fact lookup vs. conceptual explanation). For example, if you split a legal contract paragraph into fixed 200-token slices you may break a single legal clause across chunks (fragmentation). Conversely, slicing a medical dosage table into token-sized pieces (cell-by-cell) will destroy the relational structure and make retrieval of the correct dosage unreliable. Use fixed-size for quick baselines, but add metadata (section/title), and a small overlap to protect context.
4. 🔁 Recursive Chunking (Hierarchical Splits)
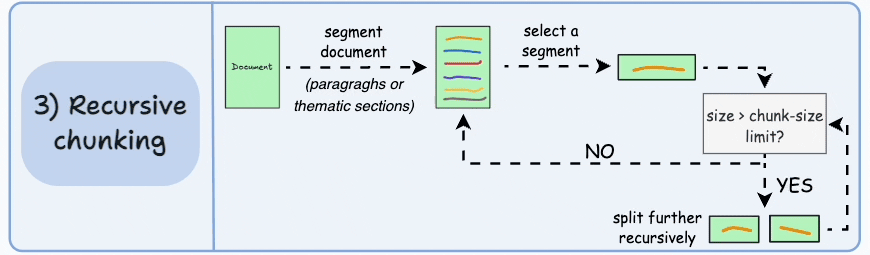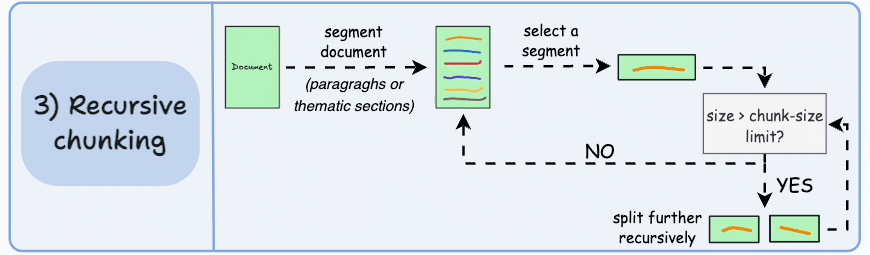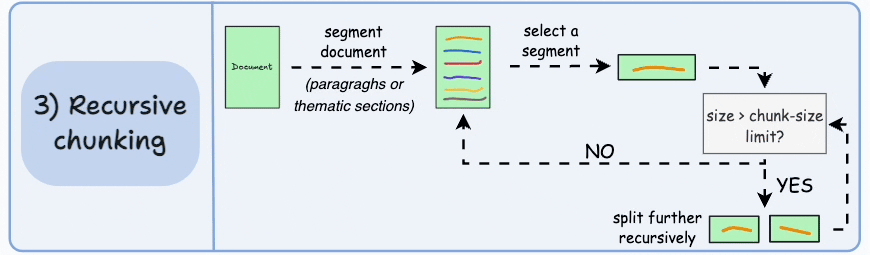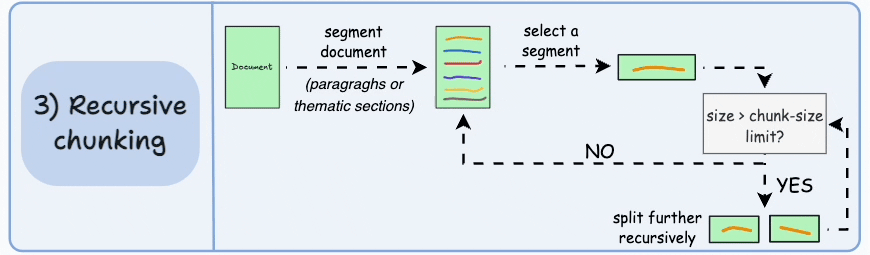
What it is Recursive (hierarchical) chunking uses natural text separators in a priority order: try splitting by largest logical units first (e.g., headings or double newlines → paragraphs), and only if a unit is still too large, split it further (e.g., sentence level → word level). LangChain’s RecursiveCharacterTextSplitter is a widely used implementation of this idea. This approach attempts to preserve human-readable boundaries while meeting chunk-size limits.
Why it helps By keeping paragraphs and section headings intact when possible, recursive splitting preserves the logical structure and makes chunks more self-contained and meaningful—so a returned chunk is more likely to contain a complete thought or answer fragment. That improves the LLM’s ability to generate correct, contextually complete responses.
Advantages
- Respects natural boundaries. Better human-like chunks (sections/paragraphs) than blind token slicing.
- Easier debugging & metadata alignment. Chunks naturally map to headings/sections for filtering or reranking.
Pitfalls
- Still rigid vs meaning. Recursive splitting enforces syntactic boundaries, but those boundaries don’t always match semantic topic shifts — so it can still produce chunks that mix concepts or split a conceptual unit across boundaries.
- Edge cases in noisy documents. Documents with poor formatting (OCR output, flattened HTML) can defeat separator logic, requiring extra cleaning. Practical tip Combine recursive splitting with light postprocessing: add a short chunk summary, keep source headings in metadata, and use modest overlap to avoid losing the start/end context of sections. This approach keeps the benefits of structure while reducing fragmentation.
5. 🧩 Semantic Chunking (Clustering / Topic-Aware Splits)
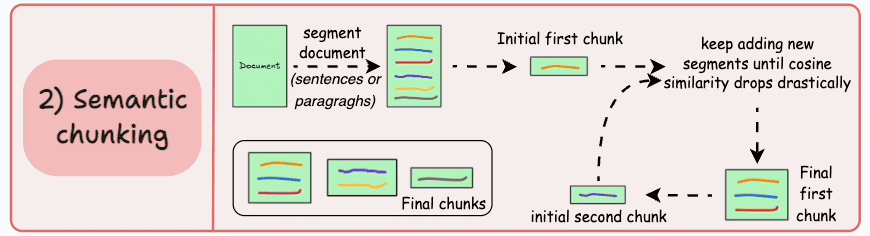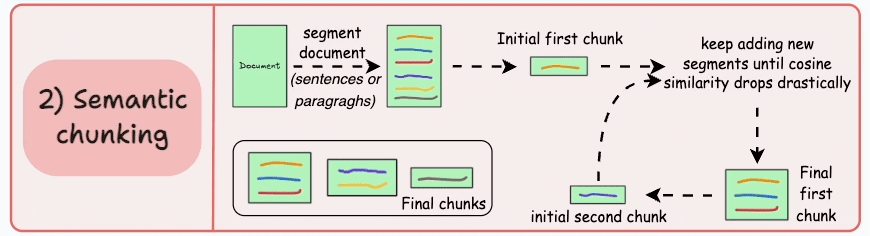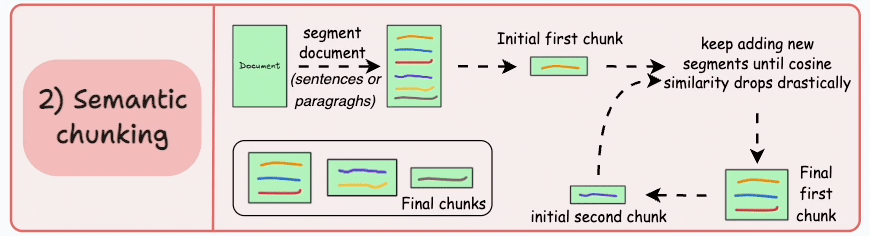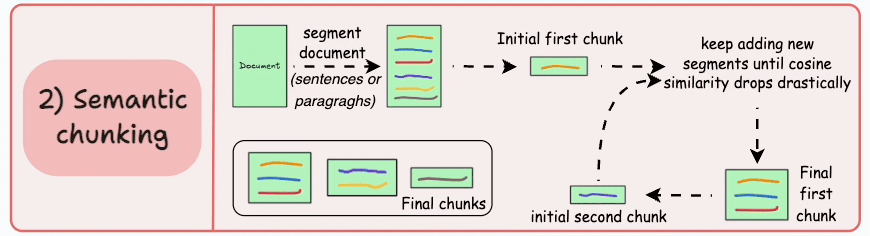
What it is Semantic chunking groups text into chunks based on meaning rather than fixed size or raw separators. Typical methods include embedding-based segmentation (e.g., sliding windows + clustering of sentence embeddings), topic models for feature extraction, or other unsupervised text-segmentation techniques that detect topical boundaries. The goal is that each chunk represents a single coherent concept or theme.
Why use it When chunks align with semantic topics, retrieval returns pieces that directly answer specific queries, reducing noise and improving answer relevance—especially for knowledge-intensive, multi-topic documents. Several recent studies and engineering reports show gains when chunks preserve semantic unity (though results can vary by task and data).
Common methods
- Embedding clustering. Compute sentence/paragraph embeddings then cluster contiguous sentences that form a coherent topic.
- Topic modeling / NMF. Use NMF or LDA to surface dominant topics and cut chunks along topic boundaries.
- Hybrid segmentation. Start with recursive splitters, then merge/split segments based on embedding similarity to neighboring segments.
Advantages
- Keeps concepts intact. Chunks are semantically meaningful answers by themselves.
- Reduces retrieval noise. Because similarity is computed over more focused semantic units, top-k results are more likely to be relevant.
Pitfalls
- Compute & complexity. Semantic segmentation requires additional embedding and clustering logic at ingest time (more CPU/GPU), and it requires hyperparameter tuning (cluster sizes, minimum chunk length). Some research even shows mixed gains vs cost depending on the dataset and task.
- Parameter sensitivity. Topic granularity and clustering hyperparameters materially affect outcomes—there’s no one-size-fits-all.
Mini case study (qualitative) Teams that switched from fixed-size slices to embedding-aware segmentation often report clearer Q&A behavior: queries that previously returned partial fragments now return single topical chunks that the LLM can use to answer fully. However, the improvement is data-dependent—semantic chunking shines on multi-topic long reports, but may not justify the extra cost for short FAQs or small corpora. (See comparative evaluations and caveats in recent literature.)
6. 📊 Special Case — Tables & Structured Data
Why tables are different Tables are relational: the meaning often arises from the row/column relationships, not from any single cell. Splitting a table cell-by-cell or tokenizing rows naively destroys that structure and makes it hard for a retriever and LLM to reconstruct the intended answer. Many teams find that “text chunking” rules fail when applied to tabular content.
Best practices
- Keep logical tables whole. Preserve the table (or logical subtable) as a single chunk when feasible so row/column semantics remain intact. If the table is very large, split it into meaningful sub-tables (e.g., by section, by subject, or by row groups), not by fixed token slices.
- Create a text summary + structured representation. Pair the table chunk with a short textual synopsis (one or two sentences) and a JSON representation of important rows/columns stored in metadata — this gives the LLM immediate context and a machine-friendly structure for extraction.
- Rerank or use a specialized ranker. After vector retrieval, use a reranker or a cross-encoder that understands table semantics (or a small rule engine) to surface the most relevant rows/cells for the LLM. This reduces mismatch between the returned chunk and the user question.
Example A medical dosage table should usually be kept as a single chunk (or split by drug class) rather than tokenized. If you split the table into small slices, a dosage lookup query may return only a fragment (e.g., a dose label without the matching measurement or indication), increasing hallucination risk. Keeping the table intact or adding a short text summary preserves the relationships the LLM needs to produce safe, accurate answers.
7. 📊 Comparing the Strategies
To make the trade-offs clearer, here’s a side-by-side summary of Fixed-size, Recursive, and Semantic chunking strategies:
| Dimension | Fixed-Size | Recursive | Semantic (Clustering / Topic-Aware) |
|---|---|---|---|
| Accuracy | Low–Medium (risk of fragmentation or noise) | Medium–High (respects natural structure) | High (chunks aligned with meaning, reduces noise) |
| Speed | Fast (light preprocessing) | Medium (extra parsing but still efficient) | Slowest (embedding + clustering at ingest) |
| Scalability | Very high (simple to scale across millions of docs) | High (depends on document formatting quality) | Medium (computationally heavier, scaling costs grow) |
| Cost | Lowest (uniform embeddings) | Medium (slightly more splits) | Highest (additional embeddings + clustering/segmentation) |
| Complexity | Very simple (easy to implement) | Moderate (requires structured splitting logic) | High (tuning needed, sensitive to parameters) |
👉 Bottom line:
- Fixed-size = great for speed and prototypes.
- Recursive = best when docs have clear structure.
- Semantic = strongest for accuracy-critical applications, but comes with extra cost and engineering overhead.
8. 🛠 Best Practices & Recommendations
- Start simple. Begin with fixed-size chunking (~300–500 tokens with a small overlap) as a baseline—fast and good enough for many use cases.
- Respect natural structure. For long reports, manuals, or academic papers, recursive chunking ensures chunks align with human-readable sections and improves retrieval clarity.
- Go semantic for precision. In knowledge-intensive domains (e.g., legal, medical, finance), semantic chunking (clustering, NMF, topic segmentation) often pays off with better answer relevance.
- Hybrid approaches. Don’t feel locked into one method—many production systems combine recursive + semantic (e.g., start with paragraphs, then merge/split using embedding similarity).
- Tables and structured data. Handle them as special cases: keep logical units intact, and add metadata or summaries.
📌 Remember: There is no “one best chunking strategy.” The right choice depends on your data type, query style, and latency/accuracy trade-offs.
9. 🎬 Conclusion & Next Episode Teaser
Good retrieval starts with good chunking. Without the right chunking strategy, even the most powerful embeddings and LLMs will struggle—returning incomplete answers, irrelevant context, or noisy generations.
In this episode, we explored the three major strategies—Fixed-size, Recursive, and Semantic—along with their strengths, weaknesses, and best-fit scenarios. We also looked at the special case of tables/structured data, which need their own care to avoid broken retrieval.

